
Structure
The typical structure of transformer includes a stack of encoder layers and decoder layers.
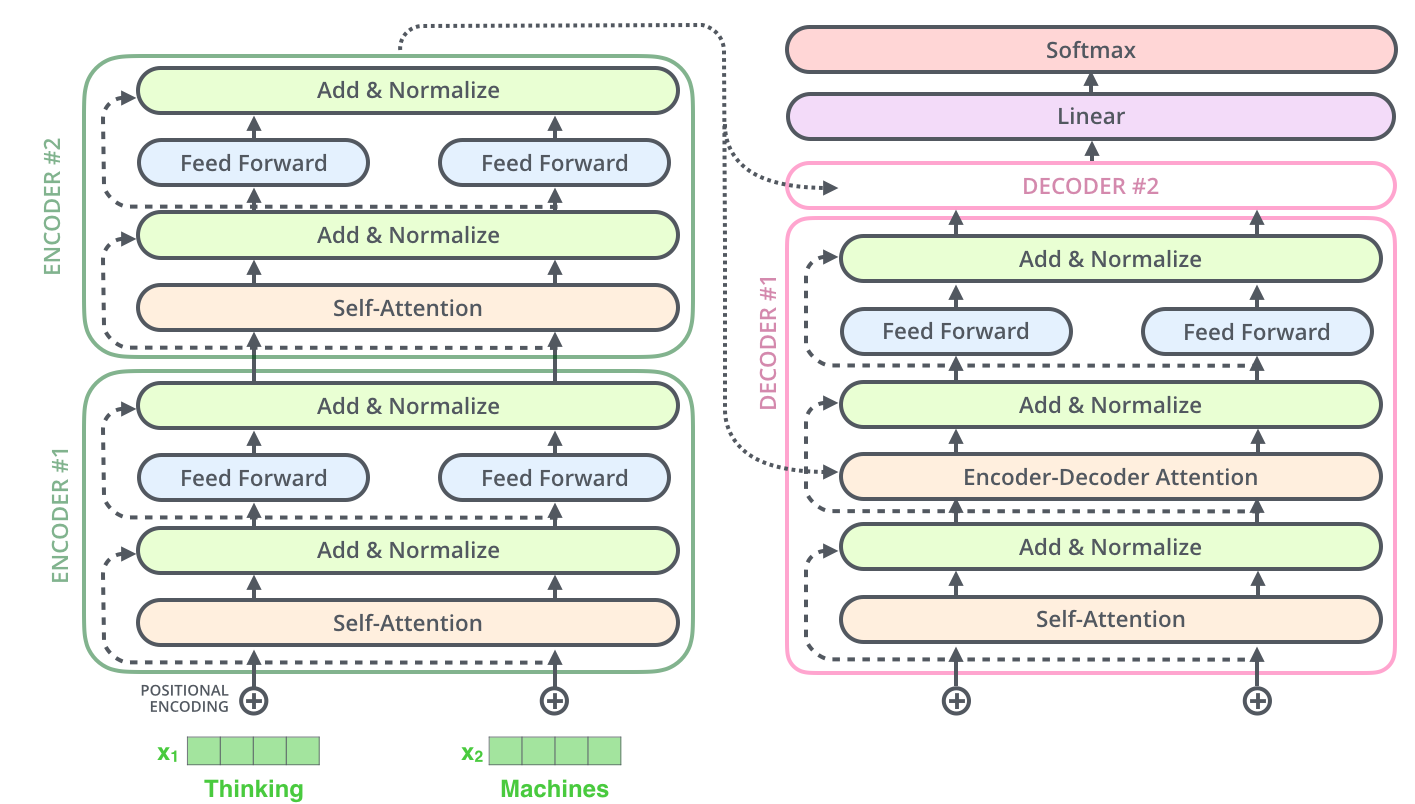
Both of the encoder and decoder have the similar architecture:
- multi-head attention
- feed-forward network
In the following paragraph, We will go through above layers in detail and give a panorama of the workflow of transformer.
Important modules
Multihead Attention
Before introducing the Multihead Attention network, we will firstly take look at a single attention network.
As the backbone of the transformer, the attention network outputs three matrix ( and are the lengths of the input and output sentences, respectively, and is the hidden dimension of the attention network):
- ,
- ,
- .
which correspond to three argument: query sentence, key sentence, score sentence. That is to say the attention network maps the embedded query matrix into (similarly for the key and score embedded matrices).
Implementation in Pytorch (simplified):
q, k, v = _in_projection(query, key, value, q_proj_weight, k_proj_weight, v_proj_weight, b_q, b_k, b_v) def _in_projection(q: Tensor, k: Tensor, v: Tensor, w_q: Tensor, w_k: Tensor, w_v: Tensor, b_q: Optional[Tensor] = None, b_k: Optional[Tensor] = None, b_v: Optional[Tensor] = None,) -> Tuple[Tensor, Tensor, Tensor]: return linear(q, w_q, b_q), linear(k, w_k, b_k), linear(v, w_v, b_v)
The core idea of the attention network is: the multiplication between and , , can denote a similarity matrix, where the element represents the similarity between the -th word in the query sentence and the -th word in the key sentence. If -th word has a strong relationship with -th word, we expect the model to learn a relatively large value in the element of the similarity matrix. This allows the model to automatically and dynamically learn the relationships among words in a sentence, known as the “attention” mechanism".
After learning the similarity matrix, we use it to multiply the score matrix , resulting in a new embedded matrix. This calculation is known as the scaled_dot_product, and can be represented as:
In multi-head attention, there are multiple single attention networks. We can view a single attention network as a convolution kernel and different attention network focus on features at different levels. If there are single attention networks and each of them outputs , , we concatenate them together and use a full connected network to map it back to the original space.
Feed-forward network
The output of the multi-head attention adds the input (the residual network) and flows through a layer-norm and full connected layer.
The residual network is designed to avoid the vanished gradient and the depth of the full connected layer is often larger than the hidden dimension in attention network (usually, ).
Workflow
Although some work only use the encoder part (e.g., see UvA Deep Learning), usually, the transformer is designed to deal with the machine translation, question-answer words in NLP. Hence, the input of the transformer contains a source sentence and a target sentence.
Transformer Encoder
The encoder extracts feature from the source sentence. There are two encoder layer in the transformer encoder module.
In the first encoder layer, the query, key and value sentence are same which is called self-attention. The output of the encoder layers, , will be transmitted to the decoder layer.
Transformer Decoder
The major different between decoder and encoder is that there is a additional encoder-decoder attention network. Both of key sentence and value sentence are and the query sentence is the output of the former decoder layer in the encoder-decoder attention network. The motivation of the encoder-decoder is not difficult to understand: when we answer questions, we want to utilize useful information of the questions.
Both the input of encoder and decoder includes a position coding process (see Jay Alammar-The Illustrated Transformer) and the training process in decoder involves the “teacher forcing” mechanism.
In pytorch, the structure of transformer is:
- Transformer
- transformer encoder
- encoder layers
- self-attention
- linear
- encoder norm
- transformer decoder
- decoder layers
- self-attention
- multi-head attention
- decoder norm
Both
self-attentionandmulti-head attentioninvoke theMultiheadAttentionmodule, which executes the same content in section Multihead-attention. The source code see torch-transformer.
Summary
The pivotal different between transformer and LSTM, RNN model is: In RNN and LSTM, they only consider a sequential order (forward or reverse). While, due to the attention mechanism, the transformer can handle long-range dependencies and contextual information.