本文通过阅读源代码记录对optimizer模块工作机制的分析,pytorch.__version__=1.13。
optimizer基类
SGD、ADAM等等方法都是继承了 Optimizer 这个基类,基类有一下属性
- defaults,Dict,记录了优化中需要用的
lr,momentum等参数信息 - params_group,List[Dict],待优化的参数,其中每个Dict中需要有
params关键字来记录待优化的参数 - state,记录优化器的状态信息,例如当使用动量的时候,会保存
momentum_buffer。
并实施了以下方法:
- add_param_groups,保存params_group中的待优化参数和优化所需的参数(如果没有的话,使用defaults中的默认值)
- zero_grad,梯度清零
- load_state_dict,加载优化器的参数
- state_dict,保存优化器的参数
state里面的信息保存、工作机制我个人目前还是不太熟悉。
class Optimizer(object):
r"""Base class for all optimizers.
.. warning::
Parameters need to be specified as collections that have a deterministic
ordering that is consistent between runs. Examples of objects that don't
satisfy those properties are sets and iterators over values of dictionaries.
Args:
params (iterable): an iterable of :class:`torch.Tensor` s or
:class:`dict` s. Specifies what Tensors should be optimized.
defaults: (dict): a dict containing default values of optimization
options (used when a parameter group doesn't specify them).
"""
def __init__(self, params, defaults):
torch._C._log_api_usage_once("python.optimizer")
self.defaults = defaults
self._hook_for_profile()
if isinstance(params, torch.Tensor):
raise TypeError("params argument given to the optimizer should be "
"an iterable of Tensors or dicts, but got " +
torch.typename(params))
self.state = defaultdict(dict)
self.param_groups = []
param_groups = list(params)
if len(param_groups) == 0:
raise ValueError("optimizer got an empty parameter list")
if not isinstance(param_groups[0], dict):
param_groups = [{'params': param_groups}]
for param_group in param_groups:
self.add_param_group(param_group)
# Allows _cuda_graph_capture_health_check to rig a poor man's TORCH_WARN_ONCE in python,
# which I don't think exists
# https://github.com/pytorch/pytorch/issues/72948
self._warned_capturable_if_run_uncaptured = True
def add_param_group(self, param_group):
r"""Add a param group to the :class:`Optimizer` s `param_groups`.
This can be useful when fine tuning a pre-trained network as frozen layers can be made
trainable and added to the :class:`Optimizer` as training progresses.
Args:
param_group (dict): Specifies what Tensors should be optimized along with group
specific optimization options.
"""
assert isinstance(param_group, dict), "param group must be a dict"
params = param_group['params']
if isinstance(params, torch.Tensor):
param_group['params'] = [params]
elif isinstance(params, set):
raise TypeError('optimizer parameters need to be organized in ordered collections, but '
'the ordering of tensors in sets will change between runs. Please use a list instead.')
else:
param_group['params'] = list(params)
for param in param_group['params']:
if not isinstance(param, torch.Tensor):
raise TypeError("optimizer can only optimize Tensors, "
"but one of the params is " + torch.typename(param))
if not self.defaults.get('differentiable', None) and not (param.is_leaf or param.retains_grad):
raise ValueError("can't optimize a non-leaf Tensor")
for name, default in self.defaults.items():
if default is required and name not in param_group:
raise ValueError("parameter group didn't specify a value of required optimization parameter " +
name)
else:
param_group.setdefault(name, default)
params = param_group['params']
if len(params) != len(set(params)):
warnings.warn("optimizer contains a parameter group with duplicate parameters; "
"in future, this will cause an error; "
"see github.com/pytorch/pytorch/issues/40967 for more information", stacklevel=3)
# 使用set来防止每个param_group中待优化的参数多次出现。
param_set = set()
for group in self.param_groups:
param_set.update(set(group['params']))
if not param_set.isdisjoint(set(param_group['params'])):
raise ValueError("some parameters appear in more than one parameter group")
# 保存加载好defaults信息的param_group -> type is List[Dict]
self.param_groups.append(param_group)
def state_dict(self):
r"""Returns the state of the optimizer as a :class:`dict`.
It contains two entries:
* state - a dict holding current optimization state. Its content
differs between optimizer classes.
* param_groups - a list containing all parameter groups where each
parameter group is a dict
"""
# Save order indices instead of Tensors
param_mappings = {}
start_index = 0
# 记录params_group,packed的params参数保存List[index]
def pack_group(group):
nonlocal start_index
packed = {k: v for k, v in group.items() if k != 'params'}
param_mappings.update({id(p): i for i, p in enumerate(group['params'], start_index)
if id(p) not in param_mappings})
packed['params'] = [param_mappings[id(p)] for p in group['params']]
start_index += len(packed['params'])
return packed
param_groups = [pack_group(g) for g in self.param_groups]
# Remap state to use order indices as keys
packed_state = {(param_mappings[id(k)] if isinstance(k, torch.Tensor) else k): v
for k, v in self.state.items()}
return {
'state': packed_state,
'param_groups': param_groups,
}
def load_state_dict(self, state_dict):
r"""Loads the optimizer state.
Args:
state_dict (dict): optimizer state. Should be an object returned
from a call to :meth:`state_dict`.
"""
# deepcopy, to be consistent with module API
state_dict = deepcopy(state_dict)
# Validate the state_dict
groups = self.param_groups
saved_groups = state_dict['param_groups']
if len(groups) != len(saved_groups):
raise ValueError("loaded state dict has a different number of "
"parameter groups")
param_lens = (len(g['params']) for g in groups)
saved_lens = (len(g['params']) for g in saved_groups)
if any(p_len != s_len for p_len, s_len in zip(param_lens, saved_lens)):
raise ValueError("loaded state dict contains a parameter group "
"that doesn't match the size of optimizer's group")
# Update the state
id_map = {old_id: p for old_id, p in
zip(chain.from_iterable((g['params'] for g in saved_groups)),
chain.from_iterable((g['params'] for g in groups)))}
def cast(param, value, key=None):
r"""Make a deep copy of value, casting all tensors to device of param."""
if isinstance(value, torch.Tensor):
# Floating-point types are a bit special here. They are the only ones
# that are assumed to always match the type of params.
# Make sure state['step'] is not casted https://github.com/pytorch/pytorch/issues/74424
if (key != "step"):
if param.is_floating_point():
value = value.to(param.dtype)
value = value.to(param.device)
return value
elif isinstance(value, dict):
return {k: cast(param, v, key=k) for k, v in value.items()}
elif isinstance(value, container_abcs.Iterable):
return type(value)(cast(param, v) for v in value)
else:
return value
state = defaultdict(dict)
for k, v in state_dict['state'].items():
if k in id_map:
param = id_map[k]
state[param] = cast(param, v)
else:
state[k] = v
# Update parameter groups, setting their 'params' value
def update_group(group, new_group):
new_group['params'] = group['params']
return new_group
param_groups = [
update_group(g, ng) for g, ng in zip(groups, saved_groups)]
self.__setstate__({'state': state, 'param_groups': param_groups})
def zero_grad(self, set_to_none: bool = False):
r"""Sets the gradients of all optimized :class:`torch.Tensor` s to zero.
Args:
set_to_none (bool): instead of setting to zero, set the grads to None.
This will in general have lower memory footprint, and can modestly improve performance.
However, it changes certain behaviors. For example:
1. When the user tries to access a gradient and perform manual ops on it,
a None attribute or a Tensor full of 0s will behave differently.
1. If the user requests ``zero_grad(set_to_none=True)`` followed by a backward pass, ``.grad``\ s
are guaranteed to be None for params that did not receive a gradient.
1. ``torch.optim`` optimizers have a different behavior if the gradient is 0 or None
(in one case it does the step with a gradient of 0 and in the other it skips
the step altogether).
"""
foreach = self.defaults.get('foreach', False)
if not hasattr(self, "_zero_grad_profile_name"):
self._hook_for_profile()
if foreach:
per_device_and_dtype_grads = defaultdict(lambda: defaultdict(list))
with torch.autograd.profiler.record_function(self._zero_grad_profile_name):
for group in self.param_groups:
for p in group['params']:
if p.grad is not None:
if set_to_none:
p.grad = None
else:
if p.grad.grad_fn is not None:
p.grad.detach_()
else:
p.grad.requires_grad_(False)
if (not foreach or p.grad.is_sparse):
p.grad.zero_()
else:
per_device_and_dtype_grads[p.grad.device][p.grad.dtype].append(p.grad)
if foreach:
for _, per_dtype_grads in per_device_and_dtype_grads.items():
for grads in per_dtype_grads.values():
torch._foreach_zero_(grads)
def step(self, closure):
r"""Performs a single optimization step (parameter update).
Args:
closure (Callable): A closure that reevaluates the model and
returns the loss. Optional for most optimizers.
.. note::
Unless otherwise specified, this function should not modify the
``.grad`` field of the parameters.
"""
raise NotImplementedError
SGD
下面看一下SGD方法,它实施了step方法,通过调用sgd,实现随机梯度下降方法。
import torch
from torch import Tensor
from .optimizer import Optimizer, required, _use_grad_for_differentiable
from typing import List, Optional
__all__ = ['SGD', 'sgd']
class SGD(Optimizer):
def __init__(self, params, lr=required, momentum=0, dampening=0,
weight_decay=0, nesterov=False, *, maximize=False, foreach: Optional[bool] = None,
differentiable=False):
if lr is not required and lr < 0.0:
raise ValueError("Invalid learning rate: {}".format(lr))
if momentum < 0.0:
raise ValueError("Invalid momentum value: {}".format(momentum))
if weight_decay < 0.0:
raise ValueError("Invalid weight_decay value: {}".format(weight_decay))
defaults = dict(lr=lr, momentum=momentum, dampening=dampening,
weight_decay=weight_decay, nesterov=nesterov,
maximize=maximize, foreach=foreach,
differentiable=differentiable)
if nesterov and (momentum <= 0 or dampening != 0):
raise ValueError("Nesterov momentum requires a momentum and zero dampening")
super(SGD, self).__init__(params, defaults)
def __setstate__(self, state):
super().__setstate__(state)
for group in self.param_groups:
group.setdefault('nesterov', False)
group.setdefault('maximize', False)
group.setdefault('foreach', None)
group.setdefault('differentiable', False)
# 简单的decorator可以用@torch.no_grad
@_use_grad_for_differentiable
def step(self, closure=None):
"""Performs a single optimization step.
Args:
closure (Callable, optional): A closure that reevaluates the model
and returns the loss.
"""
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
for group in self.param_groups:
params_with_grad = []
d_p_list = []
momentum_buffer_list = []
has_sparse_grad = False
for p in group['params']:
if p.grad is not None:
params_with_grad.append(p)
d_p_list.append(p.grad)
if p.grad.is_sparse:
has_sparse_grad = True
state = self.state[p]
if 'momentum_buffer' not in state:
momentum_buffer_list.append(None)
else:
momentum_buffer_list.append(state['momentum_buffer'])
sgd(params_with_grad,
d_p_list,
momentum_buffer_list,
weight_decay=group['weight_decay'],
momentum=group['momentum'],
lr=group['lr'],
dampening=group['dampening'],
nesterov=group['nesterov'],
maximize=group['maximize'],
has_sparse_grad=has_sparse_grad,
foreach=group['foreach'])
# update momentum_buffers in state
for p, momentum_buffer in zip(params_with_grad, momentum_buffer_list):
state = self.state[p]
state['momentum_buffer'] = momentum_buffer
return loss
def sgd(params: List[Tensor],
d_p_list: List[Tensor],
momentum_buffer_list: List[Optional[Tensor]],
# kwonly args with defaults are not supported by functions compiled with torchscript issue #70627
# setting this as kwarg for now as functional API is compiled by torch/distributed/optim
has_sparse_grad: bool = None,
foreach: bool = None,
*,
weight_decay: float,
momentum: float,
lr: float,
dampening: float,
nesterov: bool,
maximize: bool):
r"""Functional API that performs SGD algorithm computation.
See :class:`~torch.optim.SGD` for details.
"""
if foreach is None:
# Placeholder for more complex foreach logic to be added when value is not set
foreach = False
if foreach and torch.jit.is_scripting():
raise RuntimeError('torch.jit.script not supported with foreach optimizers')
if foreach and not torch.jit.is_scripting():
func = _multi_tensor_sgd
else:
func = _single_tensor_sgd
func(params,
d_p_list,
momentum_buffer_list,
weight_decay=weight_decay,
momentum=momentum,
lr=lr,
dampening=dampening,
nesterov=nesterov,
has_sparse_grad=has_sparse_grad,
maximize=maximize)
这里sgd根据参数调用单线程或者多线程的tensor_sgd方法,传入的参数有待优化的变量列表params,和其梯度列表d_p_list,以及所需要的动量、加速等相关信息。以单线程的tensor_sgd为例,将前面的动量、加速等等信息通过in_place给梯度,最后通过params.add_(d_p, alpha=-lr)来进行梯度下降。
def _single_tensor_sgd(params: List[Tensor],
d_p_list: List[Tensor],
momentum_buffer_list: List[Optional[Tensor]],
*,
weight_decay: float,
momentum: float,
lr: float,
dampening: float,
nesterov: bool,
maximize: bool,
has_sparse_grad: bool):
for i, param in enumerate(params):
d_p = d_p_list[i] if not maximize else -d_p_list[i]
if weight_decay != 0:
d_p = d_p.add(param, alpha=weight_decay)
if momentum != 0:
buf = momentum_buffer_list[i]
if buf is None:
buf = torch.clone(d_p).detach()
momentum_buffer_list[i] = buf
else:
buf.mul_(momentum).add_(d_p, alpha=1 - dampening)
if nesterov:
d_p = d_p.add(buf, alpha=momentum)
else:
d_p = buf
param.add_(d_p, alpha=-lr)
这里对sgd中的一些参数和计算流程做出解释
- weight_decay,可以理解为为参数加入正则
- momentum,该项的公式为
- nesterov的公式是,, 。这里直接做了近似,详情参考bwangccc。
custom optimizer in pytorch
这里我自定义一个简单地针对 simplex 约束的mirror descent优化器,MD。
初始化方面我舍弃掉了momentum,nesterov,weight_decay等等参数,只保留了一个lr。
在进行step操作时,我用@torch.no_grad()这种上下文装饰器类替代基类中_use_grad_for_differentiable这个装饰器,来实现set_grad_enabled(False)不进行梯度计算。
同时我为p.grad函数加入了一个penalty(可以是一个标量或者和所有param可广播运算的tensor),同时在__single_tensor_md实现project操作。
import torch
from torch import Tensor
from torch.optim.optimizer import Optimizer, required
from typing import List, Optional
class MD(Optimizer):
def __init__(self, params, lr=required, *, maximize=False, foreach: Optional[bool] = None,
differentiable=False):
if lr is not required and lr < 0.0:
raise ValueError("Invalid learning rate: {}".format(lr))
defaults = dict(lr=lr, maximize=maximize, foreach=foreach,
differentiable=differentiable)
super(MD, self).__init__(params, defaults)
def __setstate__(self, state):
super().__setstate__(state)
for group in self.param_groups:
group.setdefault('maximize', False)
group.setdefault('foreach', None)
group.setdefault('differentiable', False)
@torch.no_grad()
def step(self, penalty, closure=None):
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
for group in self.param_groups:
params_with_grad = []
d_p_list = []
has_sparse_grad = False
for p in group['params']:
if p.grad is not None:
params_with_grad.append(p)
p.grad.add_(penalty)
d_p_list.append(p.grad)
if p.grad.is_sparse:
has_sparse_grad = True
state = self.state[p]
md(params_with_grad,
d_p_list,
lr=group['lr'],
maximize=group['maximize'],
has_sparse_grad=has_sparse_grad,
foreach=group['foreach'])
def md(params: List[Tensor],
d_p_list: List[Tensor],
has_sparse_grad: bool = None,
foreach: bool = None,
*,
lr: float,
maximize: bool
):
if foreach is None:
# Placeholder for more complex foreach logic to be added when value is not set
foreach = False
func = __single_tensor_md
return func(params,
d_p_list,
lr=lr,
has_sparse_grad=has_sparse_grad,
maximize=maximize)
def __single_tensor_md(params: List[Tensor],
d_p_list: List[Tensor],
lr:float,
maximize: bool,
has_sparse_grad: bool):
for i, param in enumerate(params):
d_p = d_p_list[i] if not maximize else -d_p_list[i]
d_p.data = torch.exp(-lr * d_p.data)
unproj = param.data * torch.exp(d_p.data)
# param.add_(d_p, alpha=-lr)
print(f"before is {param.data}")
param.data = unproj / torch.sum(unproj)
print(f"after is {param.data}")
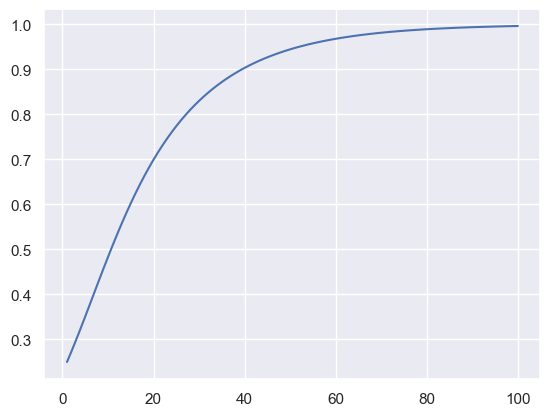
然后测试一下,得到如下图示
x = torch.tensor([[0.25, 0.75]], requires_grad=True)
y = torch.tensor([0], dtype=torch.long)
loss_fn = nn.CrossEntropyLoss()
md_optimizer = MD([x], lr=0.1)
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
for epoch in range(100):
md_optimizer.zero_grad()
loss = loss_fn(x, y)
ans.append(x.clone().detach()[0][0].item())
loss.backward()
md_optimizer.step(penalty=torch.tensor([[0.01, 0.01]]))
plt.plot(range(1, 101), ans)